Message from Leadership
This year has been an important year of transitions and laying of new foundations for Open Knowledge International (OKI). With the departure of our chief executive officer at the end of 2017, our chief product officer and chief operating officer stepped up jointly into that role. This was supported by Karin Christiansen, our board chair, who joined the leadership team as executive director and to help us complete the search for a new CEO. Which we are delighted to say has been a great success.
The purpose and mission of OKI remain the same: realising open data’s value to society by helping civil society groups access and use data to take action on social problems. However the challenges facing the open agenda are perhaps the greatest in the movement’s history. We have moved through an era of widespread support and understanding for our cause at the highest levels of governments, such as the USA and UK. We now face a situation which is increasingly closed. This closing down is affecting many sectors from those working on the future of the internet to trade and includes the challenges that key data-driven technologies such as artificial intelligence and the Internet of Things are presenting to our society and economy. This turnaround has happened faster than anyone could have anticipated. Now we need to work out how best to respond to counter these trends.
In addition to the successful work outlined below, a key feature of this year for OKI has been making sure we are ready to face the challenges that 2019 brings. We are delighted to have appointmented our new CEO Catherine Stihler. Her history of work for the European Parliament on digital policy, prioritising the digital single market, digital skills, better accessibility of digital products for the disabled, as well as citizen online data protection and privacy, will be of great inspiration and value for our organisation in the years to come. Catherine is supported by a refreshed Board with a huge breadth of skills and experience, a clarity of focus on our organisational competencies and a refreshed approach to building out opportunities which deliver on our mission through strong partnerships and exceptional delivery.

Highlights from our projects
Frictionless Data
With Frictionless Data, we focus specifically on reducing friction around discoverability, structure, standardisation and tooling. More generally, the technicalities around the preparation, validation and sharing of data - in ways that both enhance existing workflows and enable new ones - towards the express goal of minimising the gap between data and insight. We do this by creating specifications and software that are primarily informed by reuse (of existing formats and standards), conceptual minimalism, and platform-agnostic interoperability.
![]()
In March we published the Frictionless Data Field Guide providing step-by-step instructions for improving data publishing workflows. The field guide introduces new ways of working informed by the Frictionless Data suite of software that data publishers can use independently, or adapt into existing personal and organisational workflows.

In July, we announced funding from the Sloan Foundation which we have used to iterate on our work to date and to facilitate deeper integration of the Frictionless Data approach in a range of tools and workflows that enable in reproducible research. We’re also focussing on researchers themselves to support them in becoming trainers and evangelists of the tools in their field(s).
“Ensuring data availability alone is insufficient for the true potential of open data to be realised. The push from journals and funders at the moment is to encourage sharing, which is the first step towards reuse. The next step is to consider how we ensure actually reusable data. Any efforts to make it easier for researchers to prepare high quality reusable datasets, and to do so with minimal effort, are welcome. Further, tools that reduce the burden of reviewing datasets are of interest to data publishers.” - Naomi Penfold eLife
OpenSpending and the Fiscal Data Package
Making government finances more transparent remained one of our key programmes of work in 2018. In close partnership with the Global Initiative of Fiscal Transparency (GIFT) we further developed our light-weight specification that models Fiscal data, the Fiscal Data Package Specification. In May we announced the version 1 of this specification, after an extensive period of testing the specification with a variety of diverse fiscal data sources. The specification is built on the philosophy that it should be flexible and adaptable to the format in which data is being published by governments around the world.
Working closely with GIFT we work with national governments ranging from Croatia to Mexico and from South Africa to Argentina, to help them publish their budgets in the Fiscal Data Package format. The resulting data is all available on our central portal OpenSpending, which provides easy ways to find data with the OS Explorer; multiple ways of visualising the data out-of-the-box via the OS Viewer; as well as a sophisticated API for more technical users of the data.
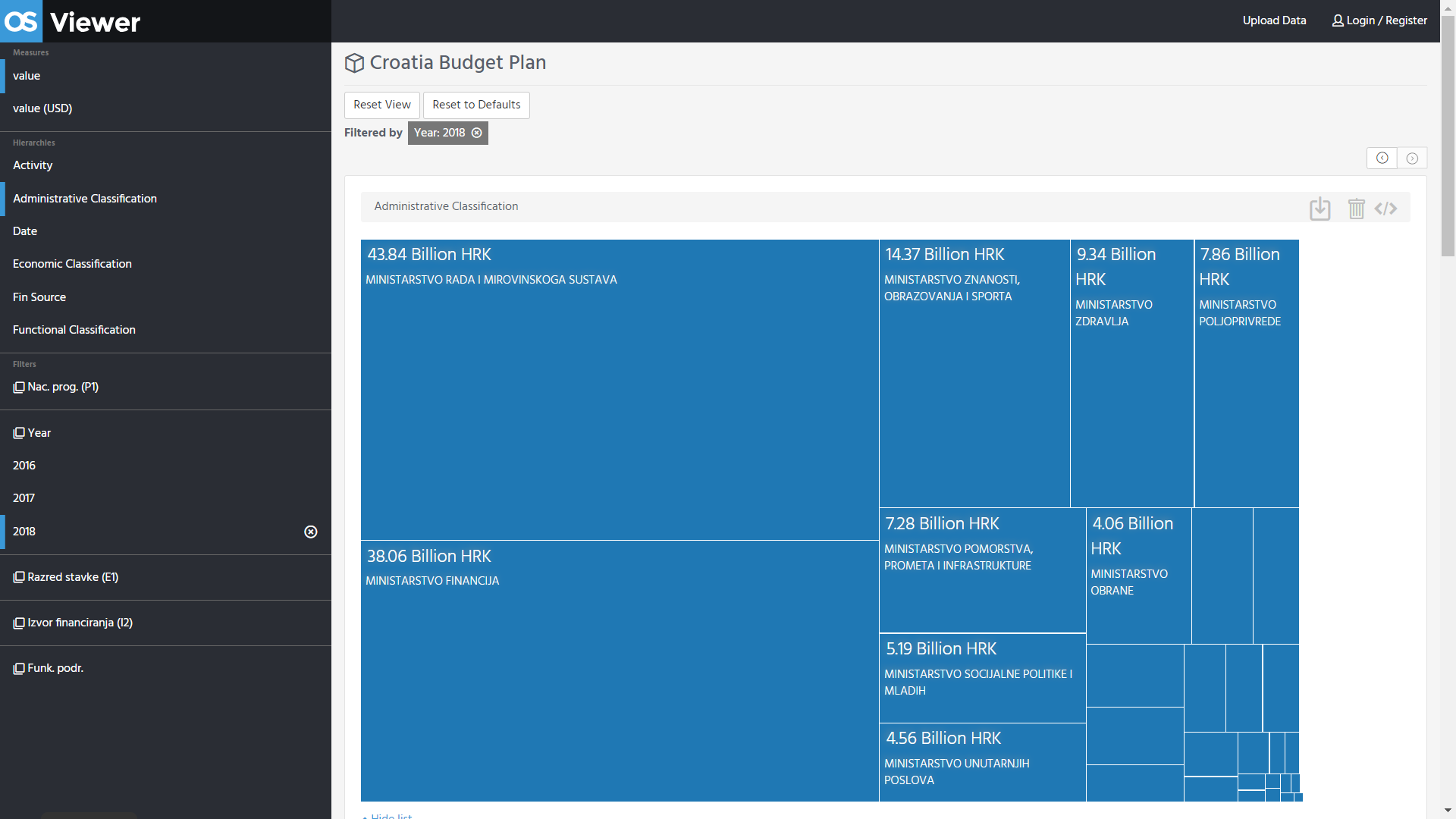 Example visualisation on OpenSpending.org of Budget data from Croatia
Example visualisation on OpenSpending.org of Budget data from Croatia
In 2019 we will continue to work closely with both publishers and users of government budget and spending data. Please get in touch with us via openspending-support@okfn.org if you would like to learn more or discuss a potential collaboration.
School of Data
School of Data is a global network dedicated to advancing data literacy in civil society. Since 2012, we have been working with CSOs and journalists to amplify their work with data: raising awareness of its possibilities and teaching the skills required, and training trainers how to pass this knowledge on.

In 2018, we ran the sixth edition of our annual fellowship programme, in which we aim to recruit and train the next generation of data leaders and trainers to magnify the reach of our data literacy programme. This year, we continued the thematic approach pioneered by the 2016 class and therefore recruited individuals who already possessed experience in a specific area of data literacy training - for example: extractives data - and with established practitioners already working within this field. We recruited some fantastic applicants for our class of 2018 fellows who are based in Bolivia, Tanzania, Guatemala, Kenya, Malawi, the Philippines, Ghana and Indonesia. We partnered with organisations interested in working on the fellows’ respective themes in the region local to them, who have provided the fellows with guidance, mentorship and expertise.
Instead of our annual Summer Camp, this year we held two events in Nairobi, Kenya and Manila, the Philippines. In both cases, members of our coordination team travelled out to meet up with groups of fellows for onboarding, workshopping and mapping out the shape of each fellow’s programme. This also gave the fellows an opportunity to meet their peers, build contacts and share their skills.
In other highlights, we designed and produced a modular curriculum to develop foundational data skills for students and trainers of the Local Government Training Institute in Tanzania. We did a training in Washington DC for the Data Collaboratives for Local Impact Fellows, building on the work we did with the organisation in 2017. In September, in Buenos Aires, we gave a joint talk with representatives of the World Bank and DataKind UK at the International Open Data Conference. And finally our coordination team expanded as we welcomed Yan Naung Oak, a former fellow whom we are delighted to now have working on delivering the class of 2018’s programme!
 School of Data methodology: the Data Pipeline
School of Data methodology: the Data Pipeline
Case studies
For over a decade we have been drawing on experience in technology, training, policy, and research; pioneering openness in new areas. In 2018 we published a number of case studies highlighting our work in different areas:
- Facilitating data validation and reuse: We worked with eLife to assess the quality of this published data and a way to identify issues to inform a strategy for improving data quality.
- Versatile visualisation of open budget data: We worked with IBP to build an interactive Data Explorer that allows users to visualise and interact with the data from current and previous surveys.
- Creating an open data publication toolkit: Details how anyone interested in publishing data can use the Frictionless Data software to improve the quality of their datasets.
- Celebrating open data with communities across the world: Open Data Day is an annual event organised by the open data community, which Open Knowledge International helps support and catalyse.
- Building an open database of information on all clinical trials: We worked with the Centre for Evidence-Based Medicine to build OpenTrials, an open database of information about the world’s clinical research trials.
- Frictionless publication and use of fiscal data: Anyone should be able access and analyse all fiscal data they are interested in easily. So Open Knowledge International developed the Fiscal Data Package.
- Mapping the state of open government data across the globe: Launched in 2013, the Global Open Data Index was the first major assessment of the state of open government data in the world.

Highlights from our collaborations
Open Budget Survey
In January the International Budget Partnership (IBP) published the Open Budget Survey (OBS) 2017 with an interactive Data Explorer developed for IBP by Open Knowledge International and updated with a number of technical and user experience improvements for 2018.
The OBS is the world’s only independent, comparative assessment of the three pillars of public budget accountability: transparency, oversight and public participation.
The Data Explorer, first created by Open Knowledge International in 2006 and updated for the release of this year’s survey, allows users to visualise the data from current and previous surveys in a number of different ways.
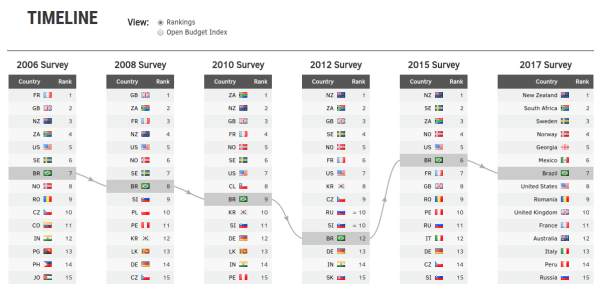 Open Budget Survey Data Explorer, Timeline view
Open Budget Survey Data Explorer, Timeline view
Citizen-generated data research
This year we worked with King’s College London and the Public Data Lab to produce Advancing Sustainability Together? Citizen-Generated Data and the Sustainable Development Goals, a report for the Global Partnership for Sustainable Development Data. The work was designed to kick-start conversations around the different approaches of doing and organising citizen-generated data (CGD). When CGD becomes good enough depends on the purpose it is used for but also how CGD is situated in relation to other data.
The report identifies several benefits CGD can bring for implementing and monitoring the SDGs, underlining the importance for public institutions to further support these initiatives.

Alongside the main report, we produced a number of other resources to support researchers and practitioners in this field. Firstly a guide for everyone interested in engaging with CGD. And secondly we gathered a list of more than 200 organisations, programs, and projects working on CGD, a raw dataset of “citizen generated data” derived from Google searches accessible on figshare, a presentation slidedeck and a Zotero group collating relevant literature.
Measurement guide
In May 2018 the Open Data Charter Measurement Guide was launched, a collaborative effort of the Charter’s Measurement and Accountability Working Group (MAWG), co-chaired by Ana Brandusescu (Web Foundation) and Danny Lämmerhirt (Open Knowledge International). It analyses the Open Data Charter principles and how they are assessed based on current open government data measurement tools. Governments, civil society, journalists, and researchers may use it to better understand how they can measure open data activities according to the Charter principles.
The Measurement Guide is available online in the form of a Gitbook and in a printable PDF version. People interested in using the indicators to measure open data can visit the indicator tables for each principle, or find the guide’s raw data here.

OpenGLAM
OpenGLAM is a global network of people and organisations who are working to open up content and data held by Galleries, Libraries, Archives and Museums. Community members from Wikimedia, Open Knowledge International and Creative Commons joined forces in the spring of 2018 to reinvigorate the OpenGLAM initiative. As a first step, contributors from different parts of the world were invited to share curation of the @openglam Twitter account to showcase and highlight the way in which OpenGLAM is being understood in different contexts. A second step was the creation of a survey to check up on the continued impact of the OpenGLAM Principles: over a hundred responses were received. In 2019, the community looks forward to updating the principles and the website, as well as having monthly OpenGLAM calls open to everyone working in the OpenGLAM field to join.
Route-TO-PA
The Raising Open and User-friendly Transparency-Enabling Technologies fOr Public Administrations project (Route-TO-PA) saw us working as part of an 11 partner network aiming to make it easier to socially interact online about open data. The project supported municipalities in their approach of using the tools SPOD (Social Platform for Open Data) and TET (Transparency-Enhancing Toolset) and included them in projects around open data. In 2018 the project was successfully completed: two of the results were selected for the European Commission’s Innovation Radar platform which promotes great EU-funded innovations:
- A new open data platform for enhancing transparency of Public Administration, offering a friendly and accessible environment to public administrators, organizations and citizens to access, reuse and publish open data (based on SPOD and TET)
- An open source and browser-based software for creating and analysing decision trees, based on the project’s SilverDecisions decision-making support tool
Following the project end, the ROUTE-TO-PA Working Group aims to continue to exploit the project results on a voluntary basis while at the same time promote open data in European public administrations.
OECD
We worked with the Organisation for Economic Co-operation and Development (OECD) to deliver in-person training and dissemination workshop to the core developer/maintainer teams at a team summit at the end of August. This introduced the team to best practices for open source development and helped them with best practices and recommendations on how to set up their project as an open source software development project.
UNHCR
We worked with the United Nations Refugees Agency (UNHCR) to build a globally-supported, centralised and secure data repository that will ensure that their team is able to use its valuable raw data to its full potential, make it available externally for our various operational partners, project stakeholders or academia, and preserving it for future use.
The project aims to retain and archive data for future use, prevent permanent loss, enable repurposing and reproducibility but also to avoid duplication and waste of resources and promote data privacy and data security. We look forward to collaborating on phase two of the project in 2019.
Rockefeller Foundation
We worked with the Rockefeller Foundation on data strategy and technical implementation to support their data outputs from funded research. The goals of the engagement so far have been to assist on socialisation of open data, data-driven research and use of data internally, as well as providing assistance with the setup and delivery of their CKAN-based data portal.
New team members
In 2018, the following members joined our Open Knowledge International team:
- Yan Naung Oak
- Helen Stewart
- Lilly Winfree
Network Highlights
Summary
The Open Knowledge Network has been growing and keeps covering more topics related to open knowledge. We welcomed a new group in Somalia and we are in the process of welcoming two new groups to the Open Knowledge Network.
We also hosted a series of community calls in the OK Virtual Summit in May 2018. We had the chance to talk to most of our active Network members about priorities, how they see the Network and why it still makes sense to belong to the OK Network. We are always eager to hear about the amazing work that the Network members do.
Open Knowledge International Events
Open Data Day 2018
The eighth edition of Open Data Day took place in March: an exciting milestone for the open data communities and a great opportunity to put open data into action. A total of 406 events were registered on our world map, almost 100 more events than 2017. We have noticed growth mostly in the global south, specifically in African and Latin American countries.
45 events received funding through the Open Data Day mini-grants funding provided by SPARC, the Open Contracting Program of Hivos, Mapbox, the Hewlett Foundation and the Foreign and Commonwealth Office of the United Kingdom. For 2018, the focus was on four key areas that open data can help solve: following public money flows, open research data, open mapping, and equal development. Based on the information provided by the groups that requested a mini-grant, most of them were organising an Open Data Day event for the first time.
To increase connections between groups, we set up a blogging schedule that connected the different events. Mini-grantees were linked to each other based on a similarity in topic, location or type of event. This resulted in a series of Open Data Day blogposts that reported on activities from different angles, as well as in more contact between the different organisers – something we hope will continue beyond the actual event itself. A summary of the event was posted on our blog in June 2018.
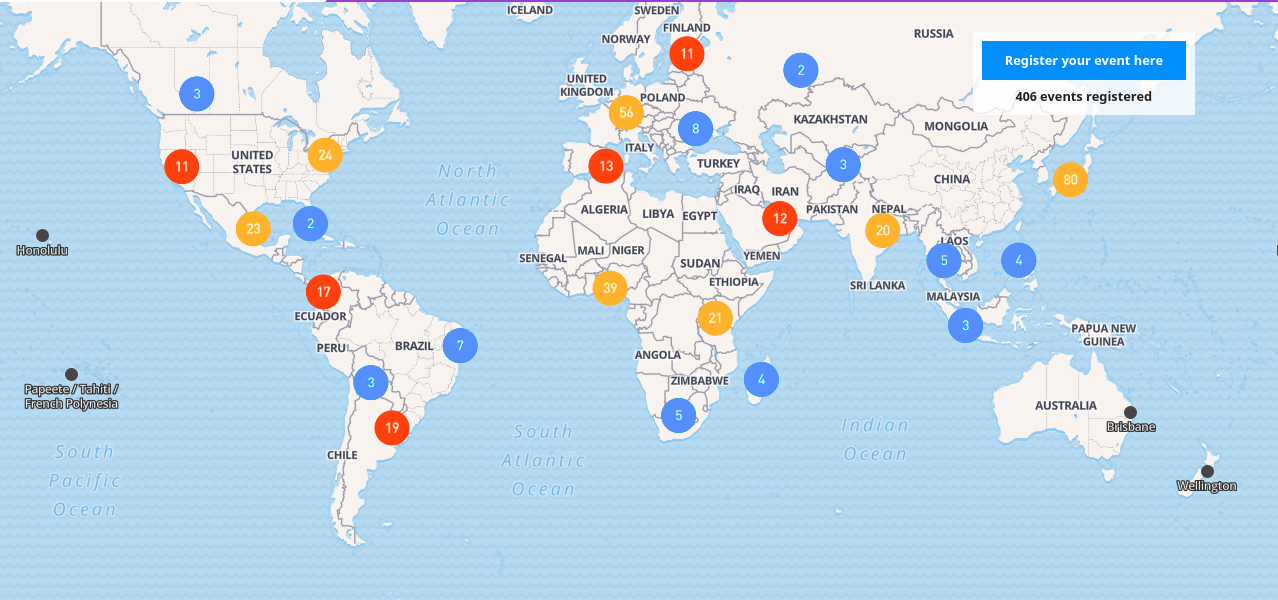
“We were really happy to support Open Data Day this year. The global open data network is so strong, inventive – and well everywhere. It’s amazing what a small grant can help happen, and very exciting to see all the reports from events roll in. For us, we even connected for this first time at Open Data Day with new Mapbox partners” - Mikel Maron, Community Team Lead at Mapbox
IODC 2018
The International Open Data Conference was a great opportunity for us to share our work, but more importantly learn from all the great minds working with Open Data across the globe. We participated in the Open Data for Development workshop, explored how to better connect budget and contracting data in the Open Contracting Partnership workshop, shared our perspective on Frictionless Data in the Data Standards workshop, and discussed developments on Open Data Infrastructure and Data Governance in a panel - specifically highlighting how important it is for governments to more strategically approach governance as an integral part of their open data policies. Lessons can be learned from leading local governments, who are in some cases more advanced than their national counterparts.

We had the chance of running a workshop on Open Washing along with members of the Web Foundation. During the workshop we discussed four main questions
- How does a particular context encourage or discourage open washing?
- How does openness serve, or not serve, non-technical communities?
- How is a lack of openness tied to culture?
- What is our role as civil society organization/infomediary or government in tackling open washing?
This session led to a great conversation about the origins of open washing in different contexts and how we can start tackling this issue. The workshop culminated in a blogpost summarising the discussion. You can read it on our blog.
Research Highlights
We investigate ways to put information into use for society. We develop methods to study data use, investigate what makes information useful and usable and explore ways of organising and collaborating around information in data communities. In the area of information politics, we test legal tools to unlock key data for society, develop collaborative databases as open laboratories for the publication of data and advance assessment methods through the Open Data Survey.
Our research is undertaken in-house, for and in collaboration with civil society groups, universities, journalists, policy-makers, and public institutions. In 2018 we published the following reports:
- The Open Data Charter Measurement Guide in collaboration with the Open Data Charter and the Web Foundation
- Advancing Sustainability Together? Citizen-Generated Data and the Sustainable Development Goals - the result of a collaboration with King’s College London, Public Data Lab and the Global Partnership for Sustainable Development Data
- Choosing and engaging with citizen generated data accompanying the above report A set of recommendations to the European Parliament and the Council to improve the PSI Directive which regulates the reuse of public sector information
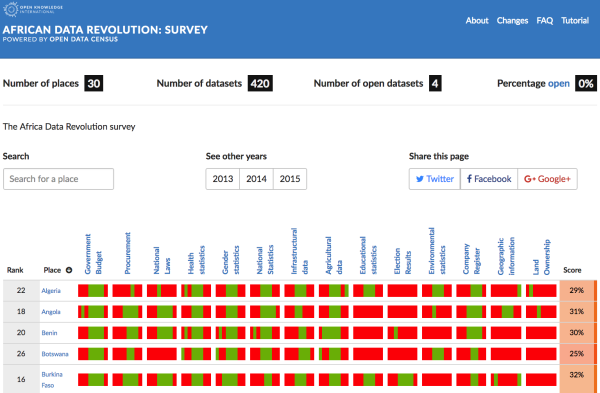
- Africa’s open government data - Findings from the Africa Open Data Index and Africa Data Revolution Report. The Africa Open Data Index (AODI), a regional version of our Global Open Data Index, collected baseline data on open data publication in 30 African countries to provide input for the second Africa Data Revolution Report.
- State of Open Data report: chapter on Open Data & Western Europe (publication forthcoming)
Multimedia
- Towards a Frictionless Data Future - Serah Njambi Rono at FORCE11 Towards a Frictionless Data Future - Serah Njambi Rono at FORCE11
- EU datathon - Sander van der Waal on Infrastructure, Standards and Governance EU datathon - Sander van der Waal on Infrastructure, Standards and Governance
- Open Data Day 2018 community call Open Data Day 2018 community call
- Route-TO-PA working group Route-TO-PA working group
- School of Data Mixlr channel School of Data Mixlr channel
- Frictionless Data: DataFlows and Data Factory walkthrough Frictionless Data: DataFlows and Data Factory walkthrough
- Frictionless Data: Data Package Creator walkthrough Frictionless Data: Data Package Creator walkthrough
- Frictionless Data: continuous data validation on the web using goodtables Frictionless Data: continuous data validation on the web using goodtables
- Frictionless Data: try.goodtables.io walkthrough Frictionless Data: try.goodtables.io walkthrough
- Frictionless Data: goodtables CLI walkthrough Frictionless Data: goodtables CLI walkthrough
How to get involved
- Over 4,000 people are members of the Open Knowledge Discuss Forum - join the discussion here!
- Looking to get hacking? Open Knowledge Labs is a community of civic hackers, data wranglers and ordinary citizens making tools and insights using open data, open content and open code. Join in!
Our community is what keeps us motivated! We want to keep you informed of what we’re working and hear what you’ve been up to. Check out the Discourse Forum for more.
We’d love to hear from you on our social media channels, including our Facebook and Twitter, or you can subscribe to receive our newsletter every two months which features updates on our projects, network and events.